For those of you who are familiar with machine learning techniques on structured data, working with unstructured data for the first time can be challenging. In this post, we’ll focus on text and how to represent it differently in order to be able to apply machine learning and deep learning techniques on it. It all comes down to 1’s and 0’s right ? Whether it is for a word or a sentence, the representation is called an embedding.
And why should I learn how to get word and sentence embeddings ? Well, imagine you have loads and loads of text data and you’re looking for a way to extract value and insight from it.
- Sentiment analysis : say if the sentiment of a text is positive or negative.
- Find the answer for a question in a pile of text.
- Check if 2 different texts are semantically similar (meaning about the same topic)
- Machine language translation.
- Natural language generation
- .. and the list keeps going.
And because there are so many different possibilities in the field, how about a summary ? Let’s start first with word embedding before tackling sentence embeddings.

Word embeddings
The whole question is how to turn a word into a numerical representation easy to be interpreted by a machine. So, imagine we have a vocabulary composed of 10 words.
( apple, eat, drink, i, is, like, popular, soccer, to, watch)
We can say that a representation for the word soccer is a one hot-vector with 1 at the word position and 0 elsewhere :
(0, 0, 0, 0, 0, 0, 0, 1, 0, 0)
Basically, the scoring method is the “absence” or “presence” of a word in a text.
And for the sentence “I like soccer” :
(0, 0, 0, 1, 0, 1, 0, 1, 0, 0)
Easy right ? But merely useful as there is no information about context, words structure or dependencies. Other than representing text, it is much more interesting to extract possible features from it. And we’ll see in each section how this is achieved by each technique.
Bag of words (BoW) – 1954
It is a representation of text that describes the occurence of words in a text and it relies on :
- A vocabulary of words
- A measure of the presence of known words.
In a nutshell, the text feature here is the word count. Example: we keep the same vocabulary as before, the representation for the sentence “I like soccer, soccer is popular” :
(0, 0, 0, 1, 1, 1, 1, 2, 0, 0)
| Pros | Cons |
| Easy to understand and explain | Very important words can be present once, compared to other meaningful words. The word count measure is not the best. |
| No information about words order or structure. |
For more, there is an excellent post here.
Term Frequency Invert Document Frequency (TF-IDF) – 1970
It is based on the intuition that if a word appears frequently in a document, it must be important and should have a high score. But if the word appears in many documents, it is likely not be as important as other words and should have a low score.
So, if we call :
- tf(i,j) number of occurrences of word i in document j. This is the Term Frequency term.
- N total number of documents
- df(i) number of documents containing word i. This is the document frequency term.
Then, the TF-IDF score of word i in a document j :
w(i,j) = tf(i,j) * log( N / df(i))
| Pros | Cons |
| Better than plain BoW, but still easy to understand | It assumes the count of different words provides independent similarity. |
| Makes no sense of similar text similarity |
For more, check out this post.
Word2Vec – 2013
Word2Vec is a shallow neural network trained to learn word associations from a large corpus of text. It produces vector representations of text that are also called feature vectors (or neural embeddings). It was developed by Tomas Mikolov in 2013 at Google.
The idea here is that similar words have similar representations (according to a similarity measure such as the cosine or euclidean distance). Similar how, you say ? Let’s say for example : the word apple is much more similar to orange than to wallet.
| Pro | Cons |
| Popular approach for sentiment analysis. | No handling of context/dependencies. |
Fore more, check out this post.
Encoder Decoder (Seq2Seq) – 2014
A sequence to sequence network is defined as the combination of 2 recurrent neural networks (based on GRU or LSTM units) which work together to transform a sequence to another. The input sentence is encoded through the first network (called the encoder) into an object called “context”, then decoded through the second network (called the decoder) to provide an output.
This was and still is considered as a huge advance in the NLP field as it made possible some challenging natural language processing tasks such as machine translation, information retrieval …
Word embeddings are obtained after training the models with labelled datasets on language modeling tasks (for example, given a word, what could be the next word ?).
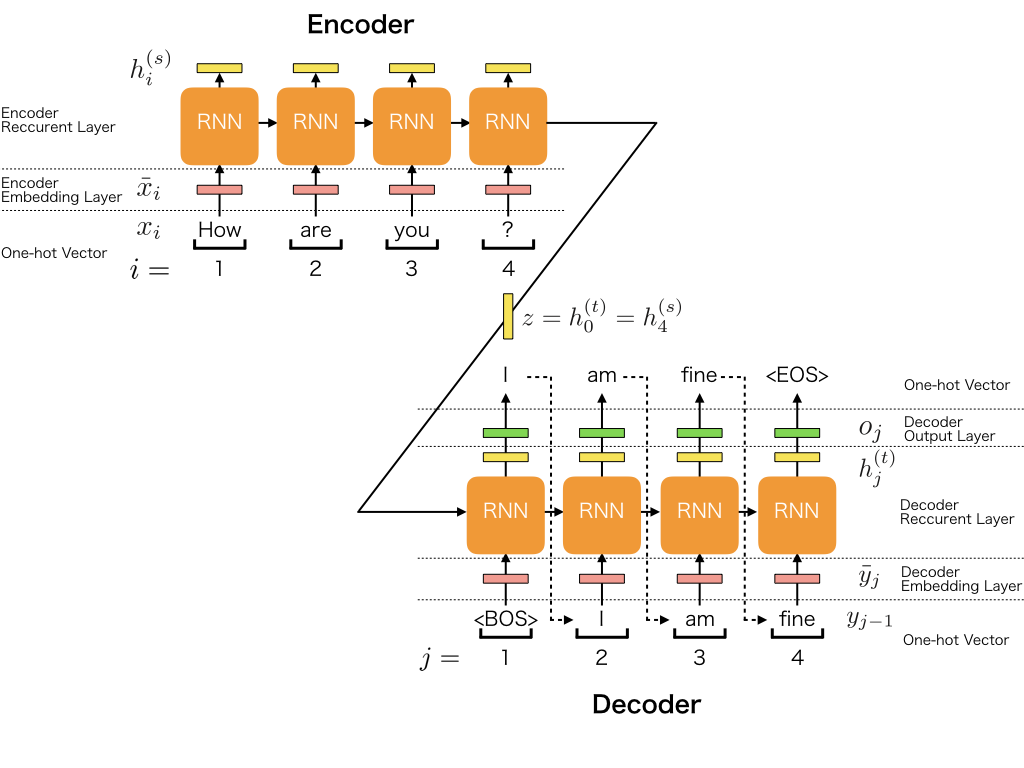
| Pros | Cons |
| Deals with long dependencies (attention mechanism) | The sequential nature prevents parallelization |
For more, check out the online training on Coursera by Andrew Ng.
Transformers – 2017
Transforms are like seq2seq models, in the sense that they are both based on an encoder-decoder architecture. However, the transformers models do not rely on recurrent networks using GRU or LSTM units. Instead, both encoder and decoder are composed of modules stacked on top of each other multiple times. The modules are composed of Multi-Head Attention and Feed Forward layers. The inputs and outputs (target sentences) are first embedded into an n-dimensional space since strings can not be used directly.
| Pros | Cons |
| Word embeddings informed by their context | |
| Parallelized computations |
An example of a transformer model is the famous BERT (Bidirectional Encoder Representations) and its variants.
A very good post about the transformers architecture is here.
Sentence embeddings
Once word embeddings are obtained, how can we get sentence embeddings? A naive solution could be to average the word embeddings composing the sentence. But this may not be always the best solution to go for. Imagine :
- “He is happy”
- “He is NOT happy”
The only difference between the 2 sentence embeddings is the embedding of the “NOT” word, which could be not significant at all. That is why this averaging solution is not the best one, especially when the word embeddings are not context-based.
Here are some proposals for sentence embeddings :
- For sentiment analysis for example, if you choose to play with word2vec embeddings, use a dense layer to get the sentence embedding instead of a simple average. A dense layer that you could train with your labeled data set.
- If you’re using seq2seq or a transformer model, you can also rely on the encoder to get your sentence embeddings. Either concatenate the hidden states from the last layers, or sum them. You can play around with the n° of layers to take into account too.
Also, keep in mind that there are already pre-trained embeddings available online, which can be fine tuned, if you have a labelled dataset. This can be very helpful if you plan to apply deep learning on a very specific task.
I hope this blog post will help you. Thanks for reading and see you soon !
